Cassandra > Basics > Underline Structure
Cassandra bases its data distribution design on Amazon's Dynamo and its data model on Google's Bigtable. In this section I will explain Cassandra's main concepts related to its data model and data distribution designs.
Node
This is the basic infrastructure component used in Cassandra where you store your data.
Data Center
A data centre in Cassandra is basically a group of related nodes. Different data centres are usually used to serve different workloads to prevent transactions from being impacted by other unrelated transactions. The replication configuration in Cassandra can be set on the data centre level or we can replicate the data across multiple data centres based on the replication factor. An example is if you have two data centres one to serve customers on the east side of the country "DC-EAST" and one to serve customers in the west side of the country "DC-WEST", but still they both share the same dataset.
Cluster
A cluster in cassandra is the outermost container and can contain multiple data centres that contain multiple nodes or machines. You can't do replicate the data across clusters.
A peer-to-peer Gossip protocol
Cassandra uses a peer-to-peer Gossip protocol that can be used by each node to discover the information and the state of the other nodes in the cluster. The protocol is a gossip protocol since the information is transferred from node to node in the cluster in a "Gossip" manner where nodes are transferring information that they know about any other nodes to their neighbours until all nodes knows about all other nodes in the cluster. This gossip information is retained and persisted in each node so that it can be used again once it restarts.
A partitioner
When you write the data to any node in a Cassandra cluster, it will be automatically sharded and distributed across all the nodes. Cassandra uses a partitioner to determine how to distribute the data across the nodes. Cassandra support multiple partitioners that can be used such as the Murmur3Partitioner. The Murmur3Partitioner uses a hash function (MurmurHash) that can be used to uniformly distribute the data across the cluster and it the default partitioner used by Cassandra since it provides faster hashing and improves the performance. So basically, the partityioners are hash functions used to compute the tokens (hashing the partition key) and later these tokens are used to distribute the data as well as read/write requests uniformally across all the nodes in the cluster based on the hash ranges (Consistent hashing).
The replication factor
When you configure Cassandra, you need to set a replication factor which is used to determine the number of copies that should be kept for each written data. The replication factor is set in the cluster level and the data will be replicated to equally important replicas (not like in a master-slave replication). Generally, you should make the replication factor greater than one but not more than the number of nodes in the cluster. For example, if you set the replication factor to 3, there will be 3 copies stored in 3 different nodes for each data written.
Replication placement strategy
Cassandra uses a replication strategy to determine which nodes to choose for replicating the data. There are different replication strategies that can be configured in Cassandra such as the SimpleStrategy or the NetworkTopologyStrategy. The SimpleStrategy is the simplest strategy where it picks the first node in the ring to be the first replica then the second node will be the next node in the ring and so forth. The NetworkTopologyStrategy is the recommended strategy since as the name indicates, it is aware of the network topology (location of the nodes in the data centres and racks). This means it is more intelligent than the simple strategy and it will try to choose different nodes in different racks for distribution which reduces the failures because usually the nodes in the same rack tends to fail together.
Snitch
Cassandra uses a snitch to listen to all the machines in a cluster and monitor nodes and network performance. Then it can provide this information about the state of the nodes to the replication strategy to decide the best nodes that can be used for replicating the data. Cassandra supports different type of snitches such as the dynamic snitch which is enabled by default. Dynamic snitch monitors the performance of the different nodes such as the read latency and then use this information to decide where to replicate and from which replica to read the data. For example if a read request has been received to one of the nodes that doesn't have the data, then this node needs to route this request to the nodes that are having the data. The node then will use the dynamic snitch information to decide to which replica node it should forward the read request.
CQL
Cassandra uses a SQL-like query language called CQL which stands for Cassandra Query Language that can be used to communicate with the Cassandra database. Additionally, Cassandra provides a CQL shell called cqlsh that can be used to interact with CQL. Cassandra supports also a graphical tool called Datastax DevCenter and many drivers for different programming languages to programatically interact with CQL.
Keyspace
Cassandra uses containers called Keyspaces which can be used to store multiple CQL tables and is closely compared to a database schema in relational databases. A good practice is to create one keyspace per application but it is also fine to create multiple keyspace per application. A Keyspace can be assigned a name and a set of attributes to define its behaviour. An example of the attributes that can be set for a Keyspace is the replication factor and the replication strategy.
A CQL table
In Cassandra, the data is stored as columns that are accessible through a primary row key. The collection of multiple ordered columns that are having a primary row key is called a CQL table.
Supported data types
CQL supports many built-in data types including a support for various types of collections such as maps, lists, and sets. Below are a list of the most used data types:
| CQL Type | Constants | Description |
|---|---|---|
| ascii | strings | US-ASCII character string |
| bigint | integers | 64-bit signed long |
| blob | blobs | Arbitrary bytes |
| boolean | booleans | true or false |
| counter | integers | Distributed counter value (64-bit long) |
| decimal | integers, floats | Variable-precision decimal Java type |
| double | integers, floats | 64-bit IEEE-754 floating point Java type |
| float | integers, floats | 32-bit IEEE-754 floating point Java type | inet | strings | IP address string in IPv4 or IPv6 format |
| int | integers | 32-bit signed integer |
| list | n/a | A collection of one or more ordered elements |
| map | n/a | A JSON-style array of literals: { literal : literal, literal : literal ... } |
| set | n/a | A collection of one or more elements |
| text | strings | UTF-8 encoded string |
| timestamp | integers, strings | Date plus time, encoded as 8 bytes since epoch |
| timeuuid | uuids | Type 1 UUID only |
| tuple | n/a | A group of 2-3 fields. |
| uuid | uuids | A UUID |
| varchar | strings | UTF-8 encoded string |
| varint | integers | Arbitrary-precision integer Java type |
Writing/reading path
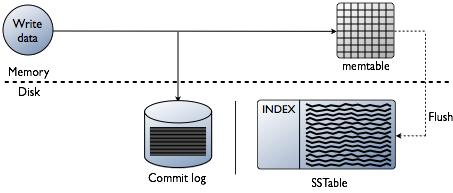
The data in Cassandra is first written to a commit log in the nodes, then the data will be captured and stored in a mem-table. Later when the mem-table is full, it will be flushed and stored in the SStable data file for durability. In the same time, all data will be replicated across all replicas in the cluster. A read operation can be done from any of the nodes, where it will first check if the data exists in the mem-table , else it will be routed to the appropriate SStable that holds the requested data. Below I will show the steps followed in Cassandra whenever a data is written:
1- First data will be appended to the commit log which will be persisted in disk and used later to recover data whenever the node crashed or shut down. The data in the commit log will be purged after the corresponding data in memtable is written to the SStable.
2- The data will be written to the MemTable which is a write back cache that Cassandra uses to look up for data before looking into the disk. The data in the MemTable will be removed whenever the MemTable reach a configurable size limit.
3- Whenever the MemTable is full and reached the size limit, the data will be flushed from the MemTable to the SSTable. Once the data is flushed from the MemTable, the corresponding data in the commit log will be also removed.
4- Then the data will be stored in the SSTable. The SSTable is immutable which means it can't be overwritten. If a row column values are updated, then a new row with another timestamp version will be stored in the SSTable. The SSTable contains a partition index to be used in mapping partition keys with the row data in the SSTable files and a bloom filter which is a structure stored in memory than can be used to check if the row data exists in the MemTable or not before searching for it in the SSTable.
The below figure shows the write path in Cassandra:
The data is deleted in Cassandra by adding a flag to the data to be deleted in the SSTable. The flag called a tombstone and once a data is marked with a tombstone, it will be deleted after a configurable time called gc_grace_seconds. The data is removed during the compaction process which will be explained in the following section.
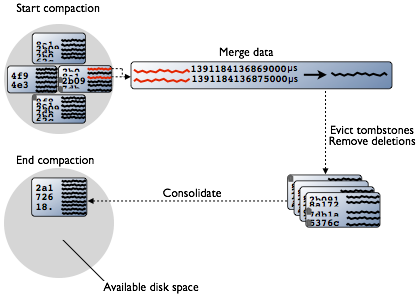
Compaction
The written data in Cassandra aren't inserted or updated in place because the data in the SSTable can't be overwritten since the SSTable is immutable. Hence, Cassandra inserts a new timestamped version of the data whenever an insert or update occurs. The new timestamped version of the data will be kept in another SSTable. Additionally, the deleted data will not happen in place but instead the data is marked with a tombstone flag to be deleted after the the pre-configured gc_grace_seconds value. Because of this, after sometime there will be so many versions available for the same row in different SSTables. Therefore, Cassandra runs periodically a process called Compaction that will merges all the different versions of the data by selecting the latest version of the data based on the timestamps and create a new SSTable. The merging is done by the partition key and the data marked for deletion will be purged from the new SSTable. The old SSTable files will be deleted as soon as the process is completed and once the final merged SSTable is available. The compaction process is show in the below figure: